Full text search is an advanced search technique that enhances query results, thereby improving the UX.
In this blog, I'll explain, using examples, how to implement full text search in Arabic, as I believe it's one of the most challenging languages for FTS, because it's a very complex language to normalize.
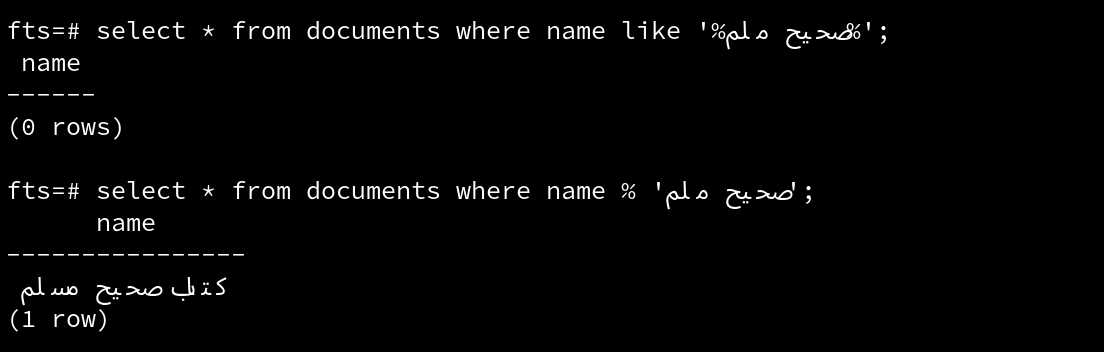
Pattern matching with LIKE/ILIKE
Pattern matching is not considered full text search (FTS), but it can be sufficient for simple projects where search is not a critical feature.
The difference between LIKE and ILIKE is case sensitivity: LIKE is case-sensitive, while ILIKE is case-insensitive.
So searching with LIKE 'Apple%' will only match Apple or Apples,
whereas ILIKE 'Apple%' will match all case variations like apples, APPLE, etc.
But arabic does not have cases, so it has no effect.
However, it can be very slow when you have a large dataset.
Triagram search
A trigram is a group of three consecutive characters taken from a string. We can measure the similarity of two strings by counting the number of trigrams they share. This simple idea turns out to be very effective for measuring the similarity of words in many natural languages - postgresql.org
it can easily be enabled by running this sql command:
CREATE EXTENSION pg_trgm; -- enable trigram search moduleYou can read more about the operators that pg_trgm provide in the official website
trigram search is a good technique for fuzzy search and handling user's typos, for example
SELECT similarity('book', 'bok'); -- returns 0.5the matching threshold is by default 0.3, and you can modify it
SELECT similarity('مكتبة', 'مكتبي'); -- returns 0.5but for arabic text as it's a complex language, sometimes pg_trgm does not give a good result, for example:
SELECT similarity('كتب', 'كتاب'); -- returns 0.2857143This is considered not a match.
Also, when the word includes diacritics (tashkeel), it is treated as completely different characters:
SELECT similarity('تشكيل', 'تَشْكِيلٍ'); -- returns 0.06666667So you should be careful and try to normalize the text, at least by removing the diacritics.
I won’t go deep into the other trigram operators that pg_trgm provides, I'll probably write another blog post to explore trigram search in more detail.
That said, it's considered a good solution when you’re working with a small number of words, but it can be very slow on large texts.
Indexing
trigram search provides GIN and Gist indexes too, to make your queries way faster.
-- GIN index
CREATE INDEX trgm_idx ON table_name USING GIN (col_name gin_trgm_ops);
-- Gist index
CREATE INDEX trgm_idx ON table_name USING GIST (col_name gist_trgm_ops);final example of a book store search:
SELECT * FROM books WHERE title % 'صحيح ملم';This should return the book
if you run the same query with LIKE/ILIKE it will not return anything, and this is the good thing about trigram search, catching typo's
FTS: Basics
First of all, before understanding full text search (FTS), we must ask: why do we need it?
Full text search really shines when we want to implement a "search by meaning" feature. For example, searching for "سيارة" should also return results that mention "عربة".
Full text search in PostgreSQL is based on the match operator @@, which returns true if a tsvector matches a tsquery.
Basic example of the FTS operators:
fts=# select to_tsvector('arabic', 'كيف يسد الخيال فجوات التاريخ؟');
to_tsvector
--------------------------------------------
'تاريخ':5 'جوا':4 'خيال':3 'كيف':1 'يسد':2to_tsvecotr function converts text into a tsvector type. A tsvector is a highly optimized, sorted list of distinct lexemes along with their positions in the original document.
Normalization (Stemming/Lemmatization): It reduces tokens to their base or root forms, called lexemes. For example, "يجري," "يجرون," would all be reduced to the lexeme "جري" This allows a search for "جري" to match all its variations.
But if you noticed something, it normalized "فجوات" to "جوا", which is very very wrong, and we will come to this later, as arabic support in FTS is very poor.
a simpler example of why it's very poor:
fts=# select to_tsvector('arabic', 'يجري'), to_tsvector('arabic', 'يجرون');
-[ RECORD 1 ]----------
to_tsvector | 'يجر':1
to_tsvector | 'يجرون':1to_tsquery will return the same normalized words as tsvector to make the text consistent when performing the match
fts=# select plainto_tsquery('arabic', 'كيف يسد الخيال فجوات التاريخ؟');
plainto_tsquery
------------------------------------------
'كيف' & 'يسد' & 'خيال' & 'جوا' & 'تاريخ'as you can see it's still converting "فجوات" to "جوا".
example of the usage of both:
fts=# select to_tsvector('arabic', 'كيف يسد الخيال فجوات التاريخ؟') @@ to_tsquery('arabic', 'تاريخ');
?column?
----------
tt stands for true, as the document and query matched.
Normalization is probably the most challenging part in fts for the arabic language, as you need a good dictionaries if you want to have a good results.
FTS: Dictionaries
Dictionaries are used to eliminate words that should not be considered in a search (stop words), and to normalize words so that different derived forms of the same word will match. A successfully normalized word is called a lexeme. - postgresql.org
There are 6 main dictionaries in postgres that we can use to lexmize a word, which are:
-
Stop Words Dictionary: Eliminates common stop words in the specified language (e.g., the, of, عن, على, فـ...).
-
Simple Dictionary: The simple dictionary template operates by converting the word to lower case and checking it against a file of stop words. it's the simplest dictionary that you can get started with.
-
Synonym Dictionary: Used to replace a word with a synonym, for example we want the search for "عربة، عربية، كرهبة" be lexmized to "سيارة"
-
Thesaurus Dictionary: Same as the synonym dictionary, but it supports phrases, so for example "المدينة المنورة" want it to be "المدينة"
-
Ispell Dictionary: The Ispell dictionary template supports morphological dictionaries, which can normalize many different linguistic forms of a word into the same lexeme, converting "أكلنا، أكلتم، يأكلون" to "أكل"
-
Snowball Dictionary: Snowball dictionary is a very basic stemmer. it maps different forms of the same word to a common "stem" (e.g: connections, connective, connected, and connecting to connect).
the default to_tsvector('arabic', ...) actually uses the snowball dictionary to lexmize the word, and as you saw above it converted "فجوات" to "جوا", which is wrong.
You can try the snowball stemming in different languages in their official website
FTS: Implementation
For implementing the arabic full text search, we will use the hunspell format files, as ispell files does not exist for the arabic language.
You can download them from here
you just need the ar.dic and ar.aff
Im running postgres container using docker, so if you want to follow me, you can run
docker cp ./ar.aff ftsdb:/usr/share/postgresql/16/tsearch_data/ar.affix
docker cp ./ar.dic ftsdb:/usr/share/postgresql/16/tsearch_data/ar.dictIspell expects the files to be .affix and .dict
ftsdb is the name of container, so you are copying from your machine to the container
After that we need to copy these files to /usr/share/postgresql/16/tsearch_data
Im using Postgres V16 so make sure to run pg_config --sharedir to know where is your dir if you are not sure which version.
If you try to ls usr/share/postgresql/16/tsearch_data you will find files and templates for different languages, you can actually copy some of them and build your own.
example of a synonym dictionary file template
root@efc3952f8152:/# cat usr/share/postgresql/16/tsearch_data/synonym_sample.syn
postgres pgsql
postgresql pgsql
postgre pgsql
gogle googl
indices index*as i mentioned before, here searching for "postgres", "postgresql" or "postgre" will be lexmized to "pgsql", i.e they are the same word.
Let's go back.
Now after copying the files, we will create a custom dictionary to use that files
CREATE TEXT SEARCH DICTIONARY arabic_hunspell (
TEMPLATE = ispell,
DictFile = ar,
AffFile = ar,
-- StopWords = ar
);
CREATE TEXT SEARCH CONFIGURATION public.arabic (
COPY = pg_catalog.english
);
ALTER TEXT SEARCH CONFIGURATION arabic
ALTER MAPPING
FOR
asciiword, asciihword, hword_asciipart, word, hword, hword_part
WITH
arabic_hunspell;I commented the StopWords, because we don't have a file for it, but as an exercice you can copy a template from the tsearch_data folder and put arabic stop words in it, reconfigure it to use your custom file.
What we did above, is create a custom ispell dictionary, then create a basic settings copied from the english fts settings, and finally overwrite that configurations to make it work for our custom dictionary.
Now if we want to test the the new configurations that are using the custom files, we can run
fts=# SELECT ts_debug('arabic', 'فجوات');
-[ RECORD 1 ]-----------------------------------------------------------------------------------------------------------------------------
ts_debug | (word,"Word, all letters",فجوات,"{arabic_hunspell}",arabic_hunspell,"{جو,فجوة,جوة,جو,فجوة,جوة,جو,فجوة,جوة,جو,فجوة,جوة}")As you can see it's using our arabic_hunspell and the output is diffrent for the word فجوات
Is it good? nope, it's still not perfect, as we can see down below:
fts=# select to_tsquery('arabic', 'كتب');
-[ RECORD 1 ]---------------------------------------------------------
to_tsquery | 'كتب' | 'تب' | 'كتب' | 'تب' | 'تبي' | 'تب' | 'كتب' | 'تب'
fts=# select to_tsvector('arabic', 'يكتبون');
-[ RECORD 1 ]-----------
to_tsvector | 'يكتبون':1يكتبون is not properly lexmized and therefore the search might not give an accurate results.
Let's try to configure the synonym dictionary and see it in action
I created a file called ar.syn with this content
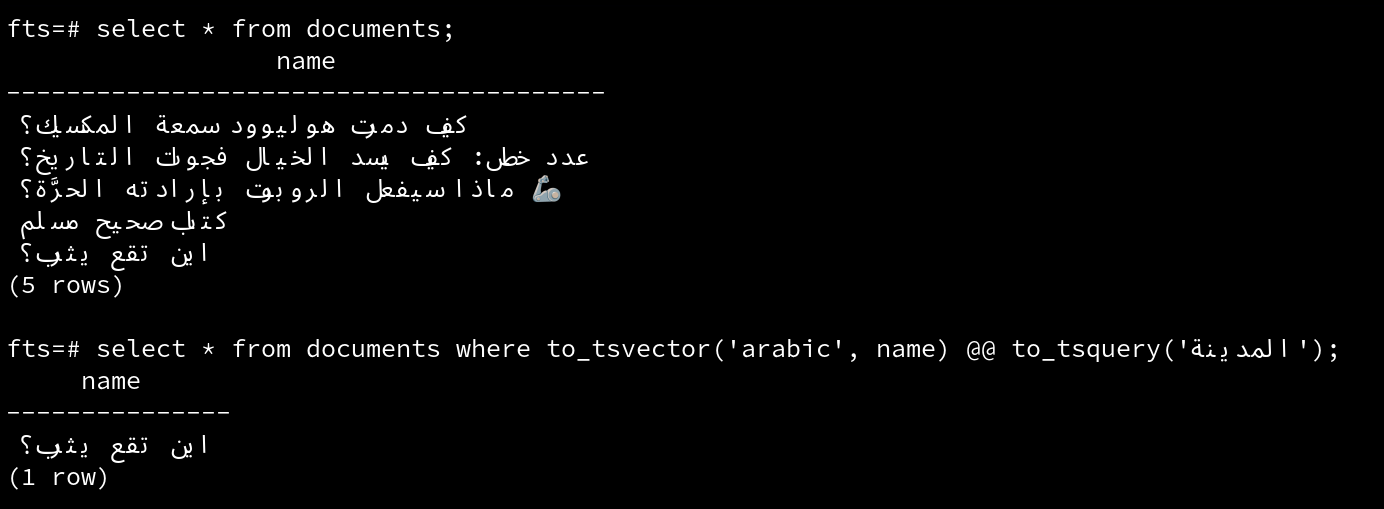
يثرب المدينة
طيبة المدينة
This is telling postgres to lexmize both words to "المدينة".
After copying the file to the tsearch directory as we did before with hunspell dictionary, we create the synonym dictionary to use this file, and change the configuration to use the synonym dictionary
CREATE TEXT SEARCH DICTIONARY arabic_syn (
TEMPLATE = synonym,
SYNONYMS = ar
);
ALTER TEXT SEARCH CONFIGURATION arabic
ALTER MAPPING FOR
asciiword, asciihword, hword_asciipart,
word, hword, hword_part
WITH arabic_syn, arabic_hunspell;
Postgres now is lexemizing the words to their synonym we defined in the file:

and this is an example of the query results in action:
FTS: Performance & Optimization
Full text search can become very slow when your data becomes too large, and therefore there 2 things you should do:
- Index: For each language you need an index in case you want to support mulitple languages
CREATE INDEX arabic_col_idx ON table_name USING GIN (to_tsvector('arabic', col_name));you can use GIST index too
- Saving the vector in the databse: to save the time lexemzing the content
CREATE TABLE my_table (
id serial PRIMARY KEY,
content text,
content_vector tsvector GENERATED ALWAYS AS (to_tsvector('arabic', content)) STORED
);Now you can just use that column directly when searching
SELECT * FROM my_table WHERE content_vector @@ to_tsquery('arabic', 'طيبة');FTS: Ranking
Ranking attempts to measure how relevant documents are to a particular query, so that when there are many matches the most relevant ones can be shown first - postgres.org
There are 2 ranking functions in postgres
ts_rank(): ranks results based on the on the frequency of their matching lexemests_rank_cd(): computes the "cover density" ranking
SELECT
name,
ts_rank_cd(to_tsvector('arabic', name), to_tsquery('arabic', 'text')) rank
FROM documents
WHERE to_tsvector('arabic', name) @@ to_tsquery('arabic', 'text')
ORDER BY rank DESCFinal review
Full text search is a powerful technique that enhances query results and the experience of your users, but as we saw some languages like arabic support is still very limited due to the nature of the language, but if you are planning to use it for other languages, you will get a super nice results especially when you mix it with the synonym dictionary.