In this blog, I'll try to explain some of the most popular keywords that have been around in the last few months.
Embeddings
Embedding is a technique used to convert digital objects like images, text, audio, etc., into a numeric representation so that the ML model can understand them.
The embedding model is a neural network model that converts the object into a list of numbers. Google has developed a model called Word2Vec, and OpenAI also provides an API that you can use.
Technically, the embedding is represented as a vector, where the distance between two vectors reflects their relatedness.

RAG
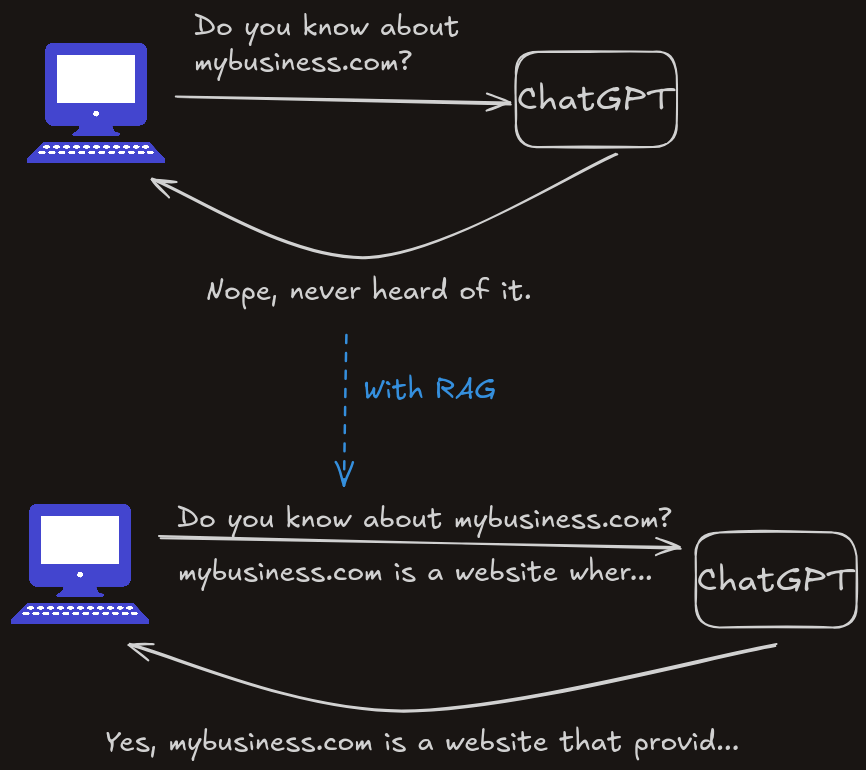
RAG, which stands for Retrieval-Augmented Generation, is another technique used to provide the LLM with information that it might not know.
For example, if you have a small business and created a website for it, and then you go to ChatGPT and ask about your business, it has to fetch the internet to find it. However, it might not find it if your website is not indexed yet.
So how does RAG work? You provide the LLM with the information it needs to answer your question in the question itself. It's as easy as that.
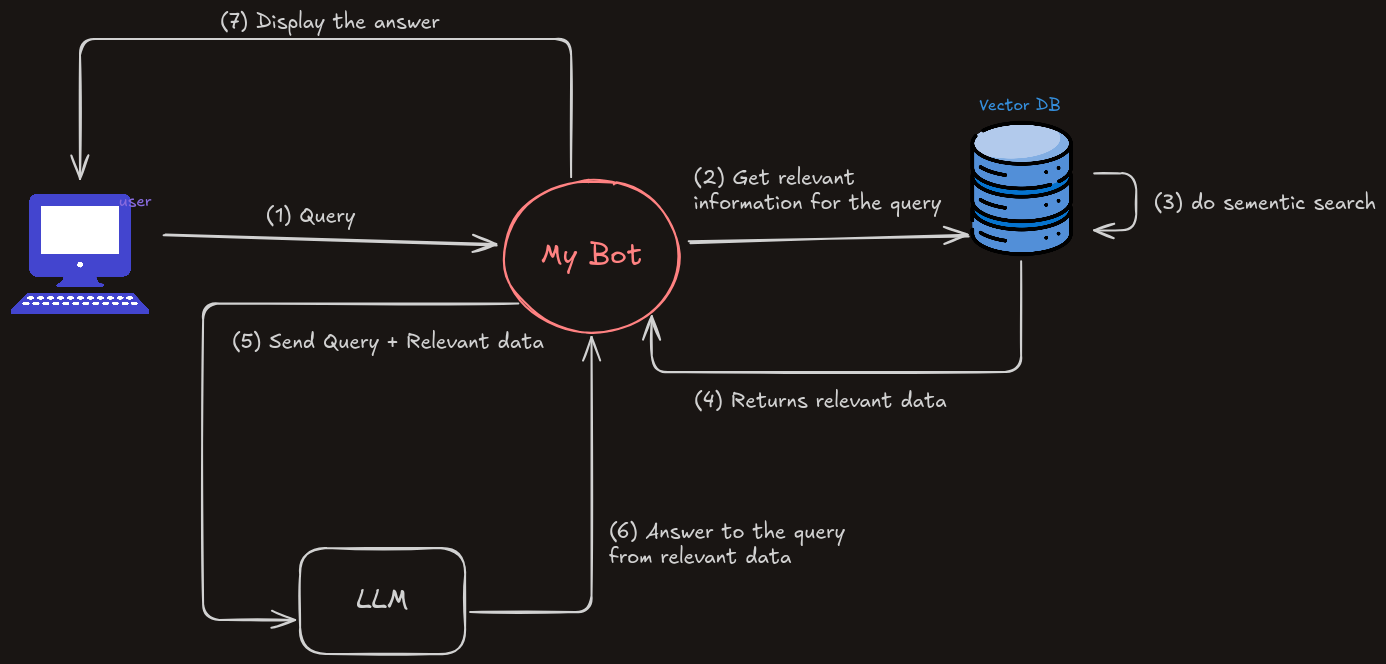
But the issue you will encounter is if you have large amounts of data that you need to provide to the LLM. For example, if you have a documentation website and want to add a chatbot that can answer users with accurate and up-to-date information.
In this case, what you need to do is provide only a piece of information that is related to the user's question.
To do so, we need to use semantic search.
Semantic search is a technique where data is retrieved based on the meaning of the query rather than simply matching text like traditional search systems (LIKE in SQL, for example).
To implement semantic search, we need to use embeddings. Remember them? What we actually need to do is convert the large data that we have into embeddings and store them in a vector database to enable semantic search.
For better semantic search results, you can chunk and summarize the data you are embedding into small pieces. For example, in a help center, you can chunk the data by section. The more chunks, the better the results, as the search will be on a specific piece of information rather than the whole page.
If we want to implement this in pseudo code, it would look like this:
const data = ["path/to/data.md", "path/to/data.pdf", "..."];
const textData = [];
for (file in data) {
const text = chunkAndSummarize(readFile(file));
textData.push(text);
}
const embeddedData = textData.map((text) => {
return openai.embedding.create({
model: "...",
input: text,
encoding_format: "float",
});
});
// Index must be created before it's used in Pinecone (index is just to separate data based on type or whatever you want)
pinecone.index.upsert([
// ...
{
vectors: embeddedData[i],
metadata: {
context: textData[i],
section: "How to install",
},
},
// ...
]);
const searchResult = pinecone.index.search(userQuery);
const llmResponse = openai.completions.create({
prompt: `
Respond to the user query: ${userQuery}
Use this information to respond:
${searchResult}
`,
});
return llmResponse.output_text;That's basically how to implement RAG. The code above is pseudo code for demonstration only. You can check the documentation of Pinecone or ChromaDB to learn how to store embedded data and search for them. Also, check OpenAI's documentation on how to create embeddings from data.
AI Agents
An AI Agent is basically an LLM that can take actions, such as executing functions, launching web browsers, etc.
OpenAI, Anthropic, and other leading LLM providers offer SDKs to build agents.
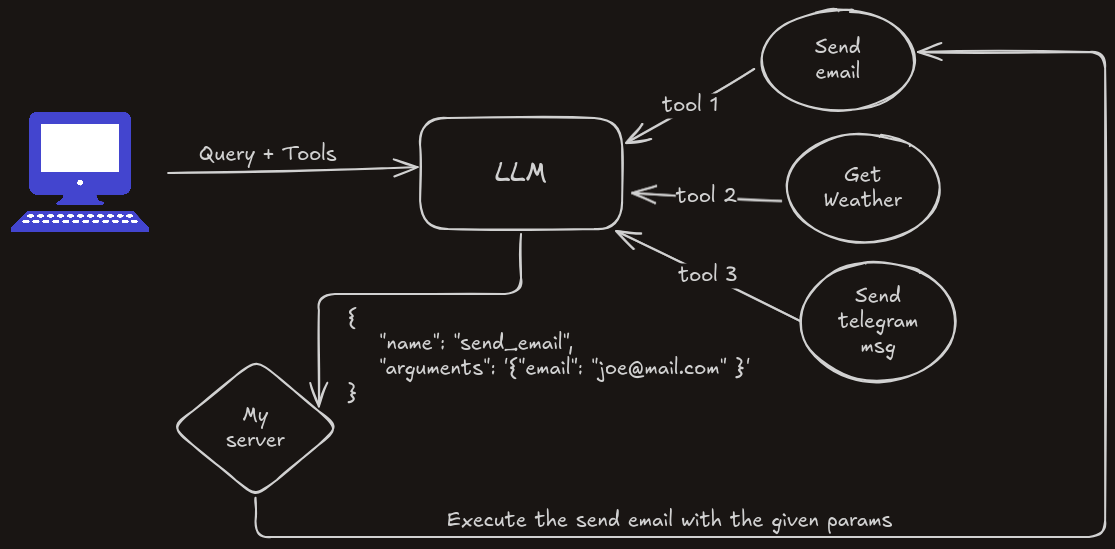
You just define the tools, which are predefined schemas of the functions you want to execute. Based on the query you provide, the LLM knows which tool should be executed.
Example of a tools schema:
const tools = [
{
type: "function",
function: {
name: "get_weather",
description: "Get the current temperature for a given location.",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "City and country, e.g., Bogotá, Colombia",
},
},
required: ["location"],
additionalProperties: false,
},
strict: true,
},
},
];The LLM does not actually execute the function. It just returns a response that contains the function name and needed arguments, and you handle the execution.
Based on what you ask the LLM, it will return a response that includes the tool you need to execute. So if you ask, "What's the weather in Sousse now?", it will return a response like this:
const llmResponse = [
{
id: "call_12345xyz",
type: "function",
function: {
name: "get_weather",
arguments: '{"location":"Sousse, Tunisia"}',
},
},
];All you have to do is execute the function.name in your code with the given arguments.
You can find a code example for implementing an AI Agent that provides the weather from a prompt.
MCP
MCP (Model Context Protocol) is simply a standard that defines how to build and interact with AI Agents.
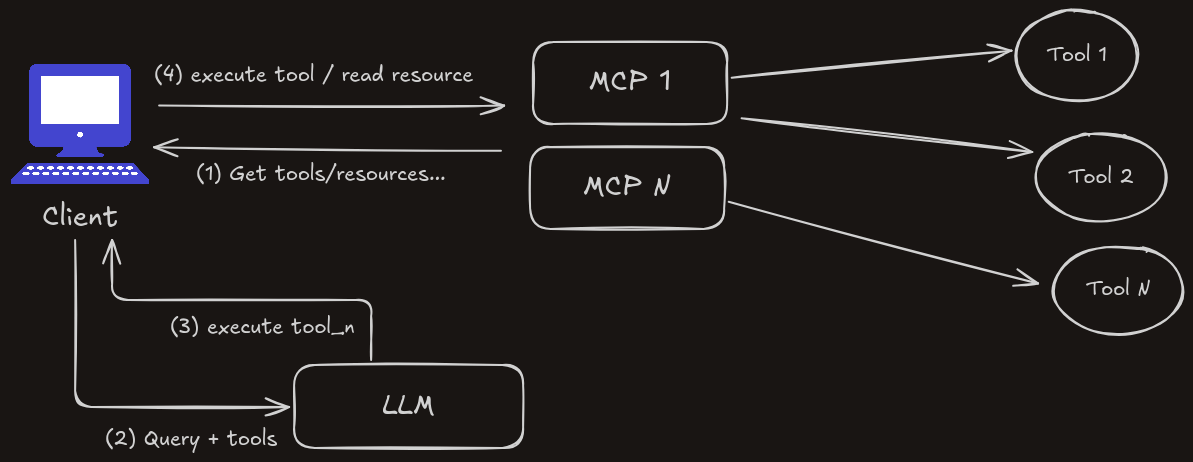
The client and the MCP server connect using a transport layer, which can either be HTTP SSE if the server is hosted on the internet or STDIO if it's on your local machine.
An example of a client is Cursor or the Claude desktop app. You can always build your own client, of course.
MCP is not just about tools; it has several features, making it a powerful standard for building AI Agents.